Cloudflare Outage on 18 Nov 2025 — What Ops Teams Need to Know
If the internet felt “off” today, you weren’t imagining it.
Cloudflare had a pretty rough morning, and because half the internet basically sits behind Cloudflare’s edge, a lot of apps went sideways at the same time.
Here’s the quick recap:
- Severity: High (as in: lots of services broke)
- Started: Around 11:20 UTC
- Root issue: Cloudflare’s own internal networking misbehaved
- Impact: ChatGPT, X, and a whole bunch of APIs got cranky
- Why it matters: When Cloudflare hiccups, the rest of us lose a few hours of our day
So what actually happened?
Cloudflare confirmed the issue was inside their own backbone — not BGP drama, not a global attack, not an upstream provider.
Something about how traffic was being delivered inside their network went wrong. Think “internal config churn + edges not getting what they need.”
When that happens, you get a cascade of fun problems:
- DNS starts timing out
- Reverse proxy sessions stall
- Turnstile and WAF challenges fail
- Telemetry becomes weird and unreliable
Basically, Cloudflare’s core got confused, and the edges started behaving like they hadn’t had their morning coffee.
What people saw out in the wild
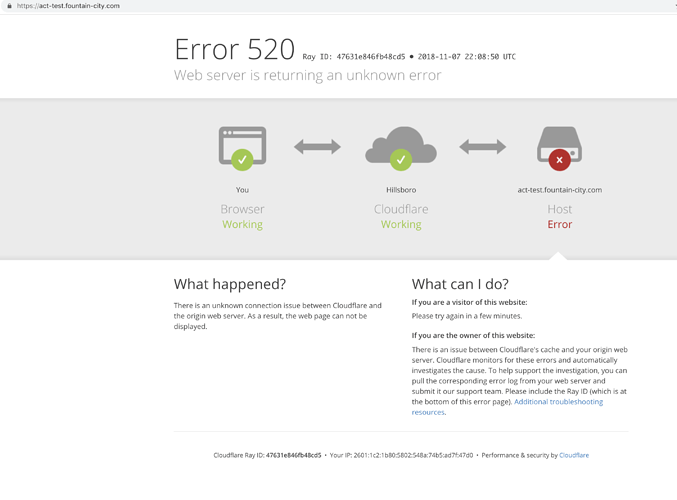
Different teams saw different kinds of breakage:
Consumer apps:
ChatGPT and X were either slow, half-broken, or throwing 5xxs.Enterprise apps / CI/CD:
Anything relying on Workers, KV, or Zero Trust tunnels got flaky — pipelines failed, deployments stalled.Security stack:
Turnstile challenges didn’t load, WAF rules misbehaved, and login flows looked haunted.Monitoring:
Dashboards lit up red, packet loss hid logs, and lots of engineers suddenly had no idea what was really happening.
What engineering teams should do next
Take a look at your logs:
Anything that interacts with Cloudflare probably had weird moments during the outage window.Run a quick failover test:
If you have multi-CDN or secondary DNS, make sure it still works.
(Outages are the best reminder to check this stuff.)Update your status page:
A simple retro helps customers know it wasn’t just your service misbehaving.Refresh your runbooks:
Add notes about:- Detecting CDN failures
- Handling WAF/Turnstile issues
- Emergency bypass steps for critical traffic flows
Check your SLA:
Some vendors require you to file outage credit requests fast. Don’t miss the window.
Final thoughts
Outages like today’s Cloudflare incident are a good reminder that even the biggest players on the internet can have messy days. What matters is how we respond: stay calm, communicate clearly, keep an eye on your systems, and learn something from the chaos.
If your team felt the impact, you’re definitely not alone. The whole internet took a bit of a wobble — and it’ll happen again someday. The best we can do is stay prepared, stay curious, and keep building resilient platforms that bounce back quickly when the world around them doesn’t.